
HTTP 的前世今生
# HTTP 的前世今生
# 前沿导读:
HTTP (Hypertext transfer protocol) 翻译成中文是超文本传输协议,是互联网上重要的一个协议,由欧洲核子研究委员会CERN的英国工程师 Tim Berners-Lee v发明的,同时,他也是WWW的发明人,最初的主要是用于传递通过HTML封装过的数据。在1991年发布了HTTP 0.9版,在1996年发布1.0版,1997年是1.1版,1.1版也是到今天为止传输最广泛的版本(初始RFC 2068 在1997年发布, 然后在1999年被 RFC 2616 取代,再在2014年被 RFC 7230 /7231/7232/7233/7234/7235取代),2015年发布了2.0版,其极大的优化了HTTP/1.1的性能和安全性,而2018年发布的3.0版,继续优化HTTP/2,激进地使用UDP取代TCP协议,目前,HTTP/3 在2019年9月26日 被 Chrome,Firefox,和Cloudflare支持,所以我想写下这篇文章,简单地说一下HTTP的前世今生,让大家学到一些知识,并希望可以在推动一下HTTP标准协议的发展。
# HTTP/0.9
HTTP 的最早版本诞生在 1991 年,这个最早版本和现在比起来极其简单,没有 HTTP 头,没有状态码,甚至版本号也没有,后来它的版本号才被定为 0.9 来和其他版本的 HTTP 区分。HTTP/0.9 只支持一种方法—— Get,请求只有一行。
- GET /hello.html
响应也是非常简单的,只包含 html 文档本身。
1. **<HTML>**
2. Hello world
3. **</HTML>**
当 TCP 建立连接之后,服务器向客户端返回 HTML 格式的字符串。发送完毕后,就关闭 TCP 连接。由于没有状态码和错误代码,如果服务器处理的时候发生错误,只会传回一个特殊的包含问题描述信息的 HTML 文件。这就是最早的 HTTP/0.9 版本。
# HTTP/1.0
1996 年,HTTP/1.0 版本发布,大大丰富了 HTTP 的传输内容,除了文字,还可以发送图片、视频等,这为互联网的发展奠定了基础。
HTTP/1.0 是怎么通过请求头和响应头来支持多种不同类型的数据呢?
有几个问题需要解决:
- 浏览器需要知道数据是什么类型, 然后浏览器才能根据不同的数据类型做针对性的处理。
- 由于万维网所支持的应用变得越来越广,所以单个文件的数据量也变得越来越大。为了减轻传输性能,服务器会对数据进行压缩后再传输,所以浏览器需要知道服务器压缩的方法。
- 由于万维网是支持全球范围的,所以需要提供国际化的支持,服务器需要对不同的地区提供不同的语言版本,这就需要浏览器告诉服务器它想要什么语言版本的页面。
- 由于增加了各种不同类型的文件,而每种文件的编码形式又可能不一样,为了能够准确地读取文件,浏览器需要知道文件的编码类型。
HTTP/1.0 的方案是通过请求头和响应头来进行协商,在发起请求时候会通过 HTTP 请求头告诉服务器它期待服务器返回什么类型的文件、采取什么形式的压缩、提供什么语言的文件以及文件的具体编码。
举例如下:
accept: text/html // 返回 html 类型
accept-encoding: gzip, deflate, br // 期望服务器可以采用 gzip、deflate 或者 br 其中的一种压缩方式
accept-Charset: utf-8 // 期望返回的文件编码是 UTF-8
accept-language: zh-CN,zh // 期望页面的优先语言是中文
服务器接收到浏览器发送过来的请求头信息之后,会根据请求头的信息来准备响应数据。不过有时候会有一些意外情况发生,比如浏览器请求的压缩类型是 gzip,但是服务器不支持 gzip,只支持 br 压缩,那么它会通过响应头中的 content-encoding 字段告诉浏览器最终的压缩类型,也就是说最终浏览器需要根据响应头的信息来处理数据。
content-encoding: br // 服务器采用了 br 的压缩方法
content-type: text/html; charset=UTF-8 // 服务器返回的是 html 文件,并且该文件的编码类型是 UTF-8。
有了响应头的信息,浏览器就会使用 br 方法来解压文件,再按照 UTF-8 的编码格式来处理原始文件,最后按照 HTML 的方式来解析该文件。
相比 HTTP/0.9,HTTP/1.0 主要有如下特性:
- 在请求中加入了HTTP版本号,如:
GET /coolshell/index.html HTTP/1.0 - HTTP 开始有 header了,不管是request还是response 都有header了。
- 增加了HTTP Status Code 标识相关的状态码。
- 还有
Content-Type可以传输其它的文件了。
一个典型的 HTTP/1.0 的请求像这样:
- GET /hello.html HTTP/1.0
- User-Agent:NCSA_Mosaic/2.0(Windows3.1)
- 200 OK
- Date: Tue, 15 Nov 1996 08:12:31 GMT
- Server: CERN/3.0 libwww/2.17
- Content-Type: text/html
- HTML
- 一个包含图片的页面
- <IMGSRCIMGSRC="/smile.gif">
- /HTML
# HTTP/1.1
在 HTTP/1.0 发布几个月后,HTTP/1.1 就发布了。HTTP/1.1 更多的是作为对 HTTP/1.0 的完善,在 HTTP1.1 中,主要具有如下改进:
- 可以复用连接
- 增加 pipeline:HTTP 管线化是将多个 HTTP 请求整批提交的技术,而在传送过程中不需先等待服务端的回应。管线化机制须通过永久连接(persistent connection)完成。浏览器将HTTP请求大批提交可大幅缩短页面的加载时间,特别是在传输延迟(lag/latency)较高的情况下。有一点需要注意的是,只有幂等的请求可以使用 pipeline,如 GET,HEAD 方法。
- chunked 编码传输:该编码将实体分块传送并逐块标明长度,直到长度为 0 块表示传输结束, 这在实体长度未知时特别有用(比如由数据库动态产生的数据)
- 引入更多缓存控制机制:如 etag,cache-control
- 引入内容协商机制,包括语言,编码,类型等,并允许客户端和服务器之间约定以最合适的内容进行交换
- 请求消息和响应消息都支持 Host 头域:在 HTTP1.0 中认为每台服务器都绑定一个唯一的 IP 地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个 IP 地址。因此,Host 头的引入就很有必要了。
- 新增了 OPTIONS,PUT, DELETE, TRACE, CONNECT 方法
虽然 HTTP/1.1 已经优化了很多点,作为一个目前使用最广泛的协议版本,已经能够满足很多网络需求,但是随着网页变得越来越复杂,甚至演变成为独立的应用,HTTP/1.1 逐渐暴露出了一些问题:
- 在传输数据时,每次都要重新建立连接,对移动端特别不友好
- 传输内容是明文,不够安全
- header 内容过大,每次请求 header 变化不大,造成浪费
- keep-alive 给服务端带来性能压力
为了解决这些问题,HTTPS 和 SPDY 应运而生。
# HTTPS
HTTPS 是以安全为目标的 HTTP 通道,简单讲是 HTTP 的安全版,即 HTTP 下加入 SSL 层,HTTPS 的安全基础是 SSL,因此加密的详细内容就需要 SSL。
HTTPS 协议的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
HTTPS 和 HTTP 的区别主要如下:
- HTTPS 协议使用 ca 申请证书,由于免费证书较少,需要一定费用。
- HTTP 是明文传输,HTTPS 则是具有安全性的 SSL 加密传输协议。
- HTTP 和 HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是 80,后者是 443。
SPDY
其实 SPDY 并不是新的一种协议,而是在 HTTP 之前做了一层会话层。
在 2010 年到 2015 年,谷歌通过实践一个实验性的 SPDY 协议,证明了一个在客户端和服务器端交换数据的另类方式。其收集了浏览器和服务器端的开发者的焦点问题,明确了响应数量的增加和解决复杂的数据传输。在启动 SPDY 这个项目时预设的目标是:
- 页面加载时间 (PLT) 减少 50%。
- 无需网站作者修改任何内容。
- 将部署复杂性降至最低,无需变更网络基础设施。
- 与开源社区合作开发这个新协议。
- 收集真实性能数据,验证这个实验性协议是否有效。
为了达到降低目标,减少页面加载时间的目标,SPDY 引入了一个新的二进制分帧数据层,以实现多向请求和响应、优先次序、最小化及消除不必要的网络延迟,目的是更有效地利用底层 TCP 连接。
HTTP/2.0
时间来到 2015 年,HTTP/2.0 问世。先来介绍一下 HTTP/2.0 的特点吧:
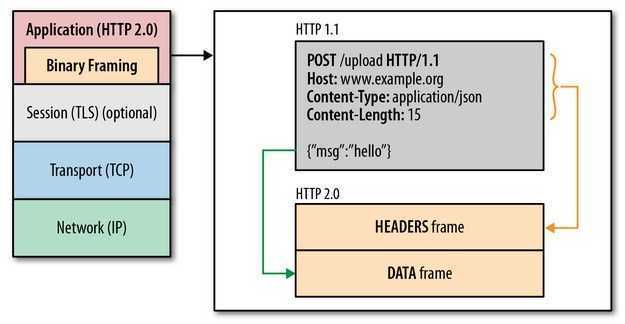
- 使用二进制分帧层:在应用层与传输层之间增加一个二进制分帧层,以此达到在不改动 HTTP 的语义,HTTP 方法、状态码、URI 及首部字段的情况下,突破HTTP1.1 的性能限制,改进传输性能,实现低延迟和高吞吐量。在二进制分帧层上,HTTP2.0 会将所有传输的信息分割为更小的消息和帧,并对它们采用二进制格式的编码,其中 HTTP1.x 的首部信息会被封装到 Headers 帧,而我们的 request body 则封装到 Data 帧里面。

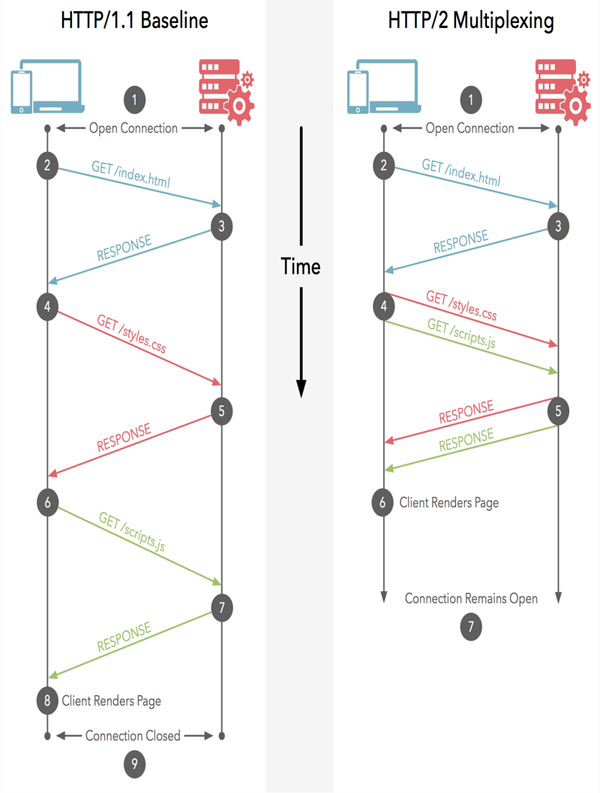
- 多路复用:对于 HTTP/1.x,即使开启了长连接,请求的发送也是串行发送的,在带宽足够的情况下,对带宽的利用率不够,HTTP/2.0 采用了多路复用的方式,可以并行发送多个请求,提高对带宽的利用率。
- 数据流优先级:由于请求可以并发发送了,那么如果出现了浏览器在等待关键的 CSS 或者 JS 文件完成对页面的渲染时,服务器却在专注的发送图片资源的情况怎么办呢?HTTP/2.0 对数据流可以设置优先值,这个优先值决定了客户端和服务端处理不同的流采用不同的优先级策略。
- 服务端推送:在 HTTP/2.0 中,服务器可以向客户发送请求之外的内容,比如正在请求一个页面时,服务器会把页面相关的 logo,CSS 等文件直接推送到客户端,而不会等到请求来的时候再发送,因为服务器认为客户端会用到这些东西。这相当于在一个 HTML 文档内集合了所有的资源。
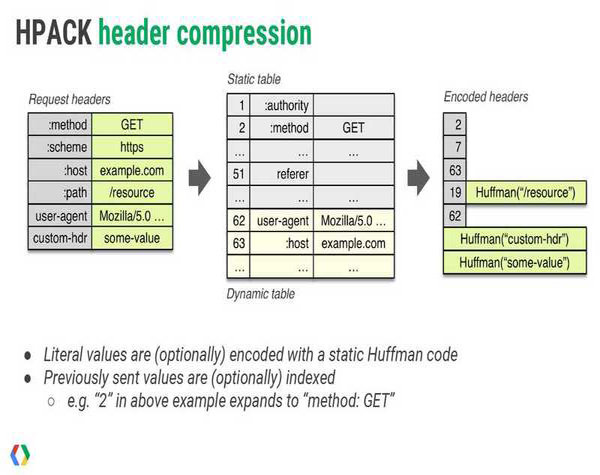
- 头部压缩:使用首部表来跟踪和存储之前发送的键值对,对于相同的内容,不会再每次请求和响应时发送。
可以看到 HTTP/2.0 的新特点和 SPDY 很相似,其实 HTTP/2.0 本来就是基于 SPDY 设计的,可以说是 SPDY 的升级版。
但是 HTTP/2.0 仍有和 SPDY 不同的地方,主要有如下两点:
- HTTP2.0 支持明文 HTTP 传输,而 SPDY 强制使用 HTTPS。
- HTTP2.0 消息头的压缩算法采用 HPACK,而非 SPDY 采用的 DEFLATE。