
JS 事件循环(Event Loop)
# JS 事件循环(Event Loop)
# 概念
JavaScript 有一个基于事件循环的并发模型,事件循环负责执行代码、收集和处理事件以及执行队列中的子任务。这个模型与其它语言中的模型截然不同,比如 C 和 Java。(摘自 MDN) (opens new window)
简单地说,对于 JS 运行中的任务,JS 有一套处理收集,排队,执行的特殊机制,我们把这套处理机制称为事件循环(Event Loop)。
为了更深刻的理解事件循环,我们先了解几个相关概念
# 单线程
我们都知道 JS 是单线程的,什么意思呢?
JS 单线程指的是 javascript 引擎(如 V8)在同一时刻只能处理一个任务。
有人或许会问,异步任务 ajax 难道不是可以和 JS 代码同时执行么?
答案是可以的,但是这和 JS 单线程并不冲突,前面说过 javascript 引擎(如 V8)在同一时刻只能处理一个任务。但这并不是说浏览器在同一个时刻只能处理一件事情,实际上 ajax 等异步任务不是在 JS 引擎上运行的,ajax 在浏览器处理网络的模块中执行,此时不会影响到 JS 引擎的任务处理。
需要强调的是,同一时刻只能处理一个任务,并不表示此时处理的只有一个函数,
我们可以有多个正在处理的函数,同时拥有多个执行环境,后面会有分析。
# 执行环境
关于执行环境可以参考
执行环境是 JS 代码语句执行的环境,包括全局执行环境和函数执行环境。
- 全局执行环境:全局环境是最外围的一个执行环境,根据 ECMAScript 实现所在的宿主环境不同,表示执行环境的对象也不一样,在 web 中,全局执行环境被认为是 window 对象。
- 函数执行环境:每个函数都有自己的执行环境。
当一个任务执行时,相应的会对应一个动态变化的执行环境栈,这个执行环境栈包括了不同的执行环境,是一个后进先出的结构。
以下面代码为例,我们看看执行环境栈的动态变化
function Fn1() {
var a = 1;
function Fn2() {
var b = 2;
}
Fn2(); // 当程序执行到此时
}
Fn1();
# 变量对象
每个执行环境都有一个变量对象与之关联(一一对应),变量对象包含了执行环境中定义的所有变量及函数。(在此处可以思考下为什么我们提倡尽量少创建全局变量,答案就是因为全局环境对应的变量对象一直会存在内存中。)
# 事件循环机制
我们先看看 MDN 上的一张图片
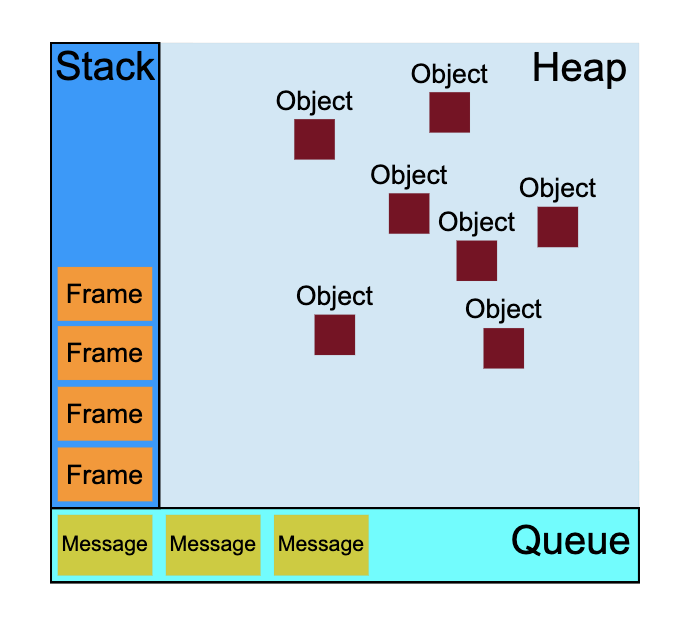
上面这张图很好地展示了 JS 中的事件循环机制,我们可以看到图中主要包括三个部分,Stack,Heap,Queue,下面逐个分析。
- Stack 表示计算机的栈结构,此处 Stack 区域表示的是当前 JS 线程正在处理的任务(一个任务)。结合执行环境部分,我们其实可以把这些 Frame 的组合当作当前的执行环境栈。一个 Frame 表示一个执行环境。这里也解释了一个任务下其实可以包含多个相关函数。
- Heap 一般用来表示计算机内存,此处 Heap 表示当前任务下相关的数据,结合上面变量对象的概念,我们可以把其中的 Object 标签当作是执行环境对应的变量对象。一个执行环境推入执行环境栈时,创建一个变量对象放入 Heap 区域,当执行环境栈推出这个执行环境时,其相对应的变量对象在 Heap 移除并销毁。如果再深入点,我们可以发现,里面 Object 的集合其实就是我们的作用域链的变量对象集合。
- Queue 在计算机中表示队列,是一种先进先出的数据结构。此处 Queue 区表示了当前正在排队的任务集合,我们称之为任务队列。一个 Message 表示一个待执行任务,它们是按顺序排队的。
分析完图片的不同区域,我们就可以很轻松地分析出这张图中阐释的事件环境机制了
1. JS 线程在同一时间只执行一个任务,期间可能创建多个函数执行环境,对应 Frame。
2. 在执行任务的时候,随时执行环境栈的动态变化,相对应的变量对象不断创建销毁,对应 Object。
3. 异步任务 ajax I/O 等得到结果时,会将其回调作为一个任务添加到任务队列,排队等待执行。
4. 当 JS 线程中的任务执行完毕,会读取任务队列 Queue,并将队列中的第一个任务添加到 JS 线程中并执行。
5. 循环 3 4 步,异步任务完成后不断地往任务队列中添加任务,线程空闲时从任务列表读取任务并执行。
# 事件循环下的宏任务与微任务
通常我们把异步任务分为宏任务与微任务,它们的区分在于:
- 宏任务(macro-task):一般是 JS 引擎和宿主环境发生通信产生的回调任务,比如 setTimeout,setInterval 是浏览器进行计时的,其中回调函数的执行时间需要浏览器通知到 JS 引擎,网络模块, I/O 处理的通信回调也是。包含有 setTimeout,setInterval,DOM 事件回调,ajax 请求结束后的回调,整体 script 代码,setImmediate。
- 微任务(micro-task):一般是宏任务在线程中执行时产生的回调,如 Promise,process.nextTick,Object.observe(已废弃), MutationObserver(DOM 监听),这些都是 JS 引擎自身可以监听到回调。
上面我们了解了宏任务与微任务的分类,那么为什么我们要将其分为宏任务与微任务呢?主要是因为其添加到事件循环中的任务队列的机制不同。
在事件循环中,任务一般都是由宏任务开始执行的(JS 代码的加载执行),在宏任务的执行过程中,可能会产生新的宏任务和微任务,这时候宏任务(如 ajax 回调)会被添加到任务队列的末尾等待事件循环机制执行,而微任务则会被添加到当前任务队列的前端,也是等待事件循环机制的执行。
其中相同类型的宏任务或微任务会按照回调的先后顺序进行排序,而不同任务类型的任务会有一定的优先级,按照不同类型任务区分
宏任务优先级,主代码块 > setImmediate > MessageChannel > setTimeout / setInterval
微任务优先级,process.nextTick > Promise > MutationObserver
举个 🌰
我们来分析下面这段代码的打印顺序
// setTimeout1
setTimeout(() => {
console.log(1);
new Promise((resolve) => {
resolve();
// Promise1
}).then(() => {
console.log(2);
});
});
// setTimeout2
setTimeout(() => {
console.log(3);
});
new Promise((resolve) => {
console.log(4);
resolve();
console.log(5);
// Promise2
}).then(() => {
console.log(6);
});
console.log(7);
new Promise((resolve) => {
resolve();
// Promise3
}).then(() => {
console.log(8);
});
我们假设这段代码正在 JS 的线程中执行(script 代码属于宏任务),在执行的时候产生了一些异步任务,setTimeout 和 Promise。其中 setTimeout 为宏任务,Promise 属于微任务。
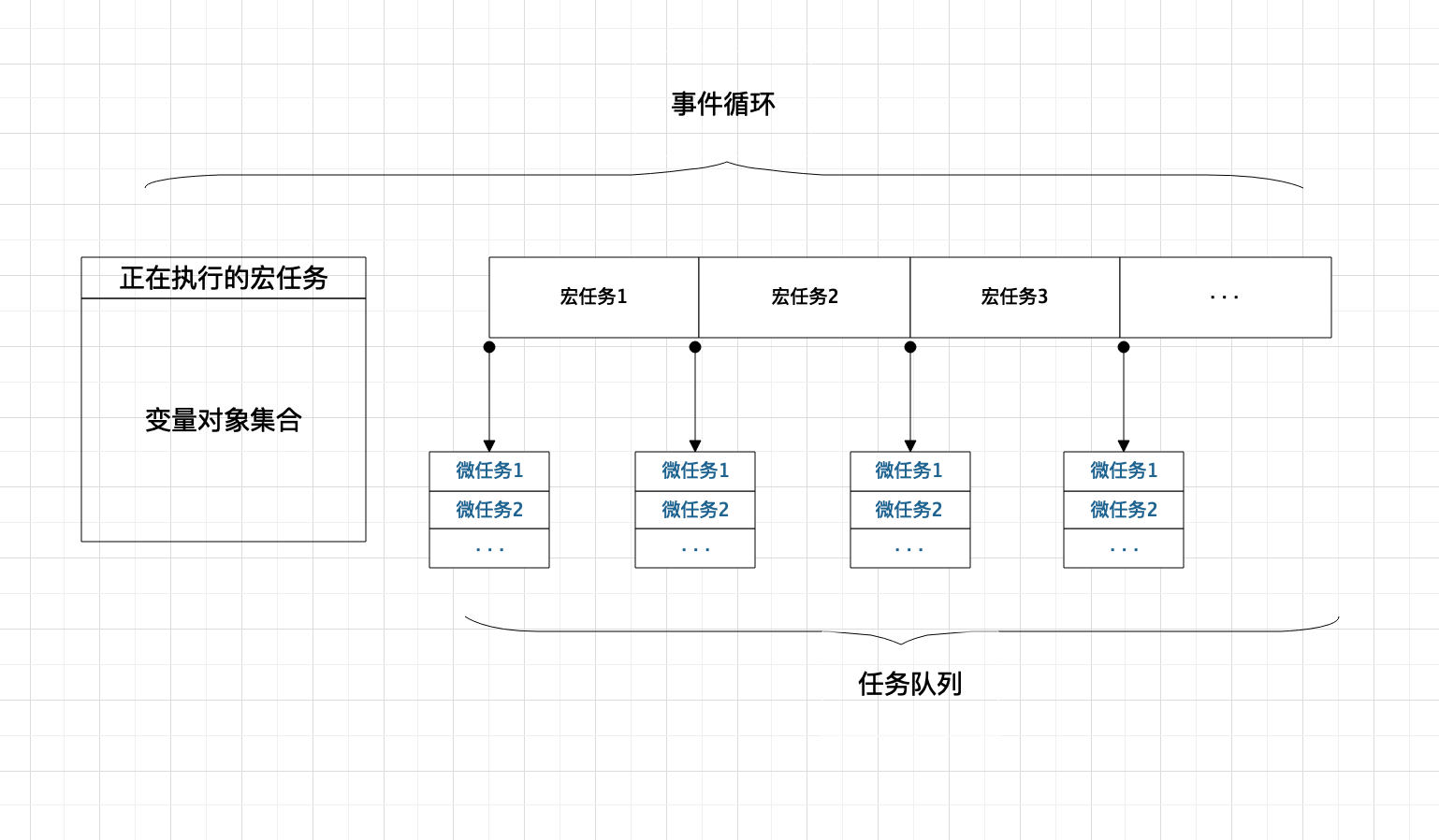
根据上面的宏任务,微任务的在任务队列的添加机制,我们可以得到在代码执行过程中的任务队列将如下所示
 分析出了任务队列后,我们就可以轻松得到打印顺序了
分析出了任务队列后,我们就可以轻松得到打印顺序了
首先执行宏任务,按照从上至下的执行顺序依次打印 4 5 7
接着按照任务队列的先后顺序执行异步任务,依次打印 6 8 1 2 3
# 深入理解 js 事件循环机制(浏览器篇)
# 抛在前面的问题:
- 单线程如何做到异步
- 事件循环的过程是怎样的
macrotask和microtask是什么,它们有何区别
# 单线程和异步
提到 js,就会想到单线程,异步,那么单线程是如何做到异步的呢?概念先行,先要了解下单线程和异步之间的关系。
js 的任务分为 同步 和 异步 两种,它们的处理方式也不同,同步任务是直接在主线程上排队执行,异步任务则会被放到任务队列中,若有多个任务(异步任务)则要在任务队列中排队等待,任务队列类似一个缓冲区,任务下一步会被移到调用栈(call stack),然后主线程执行调用栈的任务。
单线程是指 js 引擎中负责解析执行 js 代码的线程只有一个(主线程),即每次只能做一件事,而我们知道一个 ajax 请求,主线程在等待它响应的同时是会去做其它事的,浏览器先在事件表注册 ajax 的回调函数,响应回来后回调函数被添加到任务队列中等待执行,不会造成线程阻塞,所以说 js 处理 ajax 请求的方式是异步的。
总而言之,检查调用栈是否为空,以及确定把哪个 task 加入调用栈的这个过程就是事件循环,而js 实现异步的核心就是事件循环。
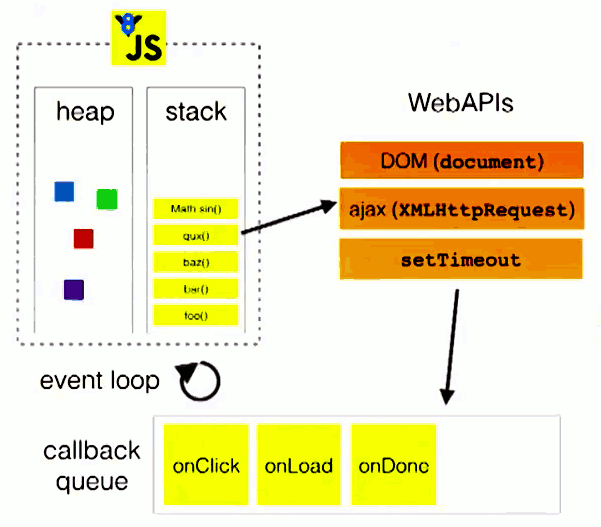
# 调用栈和任务队列
顾名思义,调用栈是一个栈结构,函数调用会形成一个栈帧,帧中包含了当前执行函数的参数和局部变量等上下文信息,函数执行完后,它的执行上下文会从栈中弹出。
下图就是调用栈和任务队列的关系图
# 事件循环
关于事件循环,HTML 规范 (opens new window)的介绍
There must be at least one event loop per user agent, and at most one event loop per unit of related similar-origin browsing contexts. An event loop has one or more task queues. Each task is defined as coming from a specific task source.
从规范理解,浏览器至少有一个事件循环,一个事件循环至少有一个任务队列(macrotask),每个外任务都有自己的分组,浏览器会为不同的任务组设置优先级。
# macrotask & microtask
规范有提到两个概念,但没有详细介绍,查阅一些资料大概可总结如下:
macrotask:包含执行整体的 js 代码,事件回调,XHR 回调,定时器(setTimeout/setInterval/setImmediate),IO 操作,UI render
microtask:更新应用程序状态的任务,包括 promise 回调,MutationObserver,process.nextTick,Object.observe
其中setImmediate和process.nextTick是 nodejs 的实现,在nodejs 篇 (opens new window)会详细介绍。
# 事件处理过程
关于macrotask和microtask的理解,光这样看会有些晦涩难懂,结合事件循坏的机制理解清晰很多,下面这张图可以说是介绍得非常清楚了。
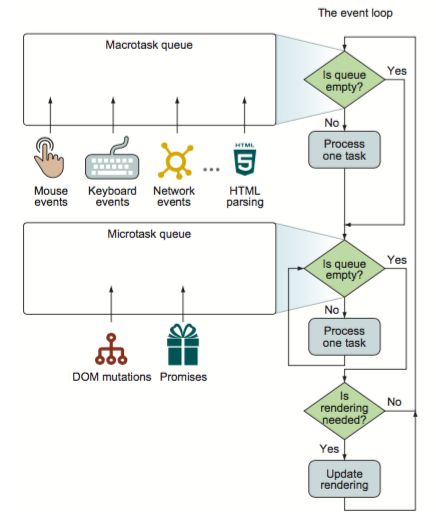
总结起来,一次事件循环的步骤包括:
1. 检查macrotask队列是否为空,非空则到2,为空则到3
2. 执行macrotask中的一个任务
3. 继续检查microtask队列是否为空,若有则到4,否则到5
4. 取出microtask中的任务执行,执行完成返回到步骤3
5. 执行视图更新
# mactotask & microtask 的执行顺序
crotask.png)
读完这么多干巴巴的概念介绍,还不如看一段代码感受下
console.log("start");
setTimeout(function() {
console.log("setTimeout");
}, 0);
Promise.resolve()
.then(function() {
console.log("promise1");
})
.then(function() {
console.log("promise2");
});
console.log("end");
打印台输出的 log 顺序是什么?结合上述的步骤分析,系不系 so easy~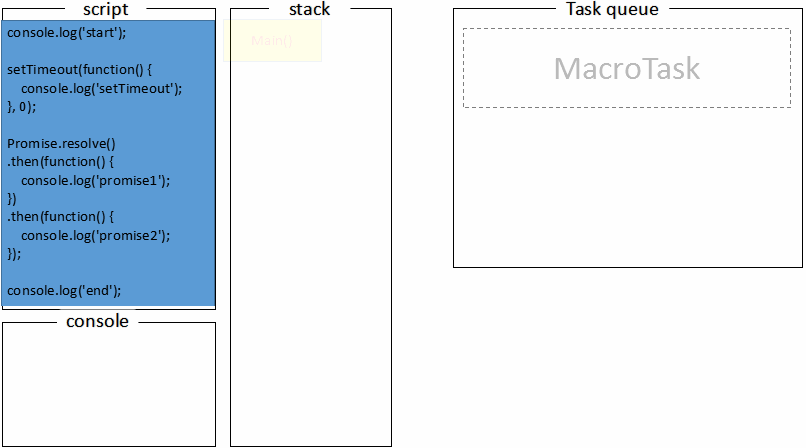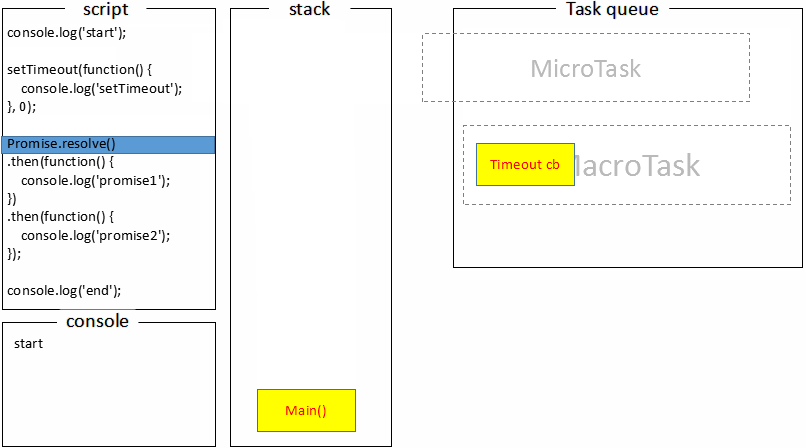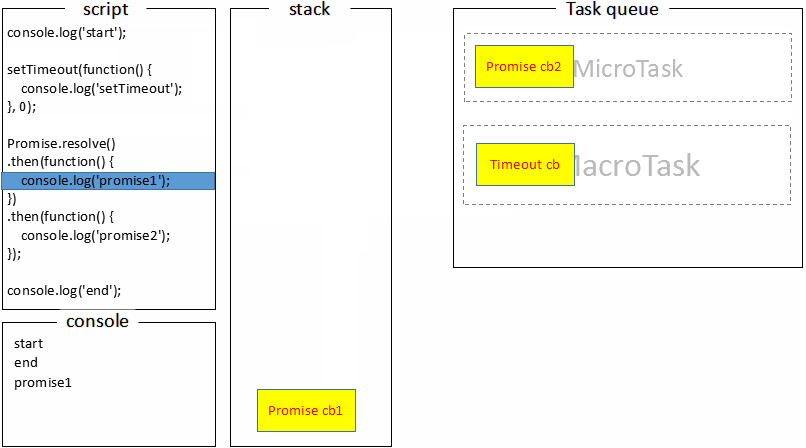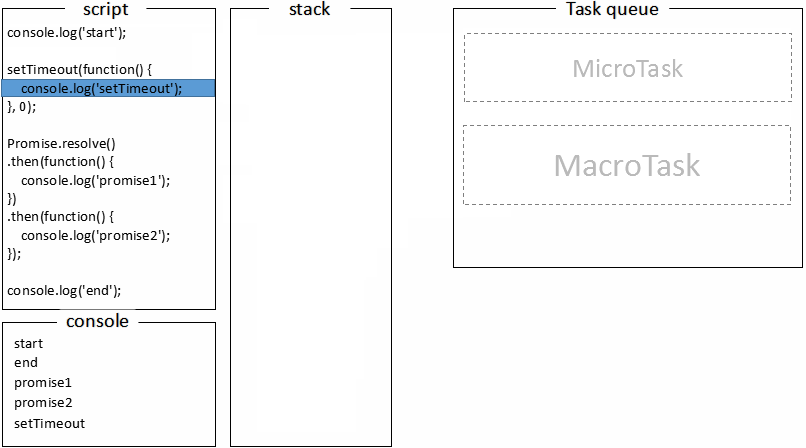
首先,全局代码(main())压入调用栈执行,打印start;
接下来 setTimeout 压入 macrotask 队列,promise.then 回调放入 microtask 队列,最后执行 console.log(‘end’),打印出end;
至此,调用栈中的代码被执行完成,回顾 macrotask 的定义,我们知道全局代码属于 macrotask,macrotask 执行完,那接下来就是执行 microtask 队列的任务了,执行 promise 回调打印promise1;
promise 回调函数默认返回 undefined,promise 状态变为 fullfill 触发接下来的 then 回调,继续压入 microtask 队列,event loop 会把当前的 microtask 队列一直执行完,此时执行第二个 promise.then 回调打印出promise2;
这时 microtask 队列已经为空,从上面的流程图可以知道,接下来主线程会去做一些 UI 渲染工作(不一定会做),然后开始下一轮 event loop,执行 setTimeout 的回调,打印出setTimeout;
这个过程会不断重复,也就是所谓的事件循环。
# 视图渲染的时机
回顾上面的事件循环示意图,update rendering(视图渲染)发生在本轮事件循环的 microtask 队列被执行完之后,也就是说执行任务的耗时会影响视图渲染的时机。通常浏览器以每秒 60 帧(60fps)的速率刷新页面,据说这个帧率最适合人眼交互,大概 16.7ms 渲染一帧,所以如果要让用户觉得顺畅,单个 macrotask 及它相关的所有 microtask 最好能在 16.7ms 内完成。
但也不是每轮事件循环都会执行视图更新,浏览器有自己的优化策略,例如把几次的视图更新累积到一起重绘,重绘之前会通知 requestAnimationFrame 执行回调函数,也就是说 requestAnimationFrame 回调的执行时机是在一次或多次事件循环的 UI render 阶段。
以下代码可以验证
setTimeout(function() {
console.log("timer1");
}, 0);
requestAnimationFrame(function() {
console.log("requestAnimationFrame");
});
setTimeout(function() {
console.log("timer2");
}, 0);
new Promise(function executor(resolve) {
console.log("promise 1");
resolve();
console.log("promise 2");
}).then(function() {
console.log("promise then");
});
console.log("end");
/* promise 1
promise 2
end
promise then
requestAnimationFrame
timer1
timer2 */
可以看到,结果 1 中requestAnimationFrame()是在一次事件循环后执行,而在结果 2,它的执行则是在三次事件循环结束后。
# 总结
事件循环是 js 实现异步的核心
每轮事件循环分为 3 个步骤:
a) 执行 macrotask 队列的一个任务 b) 执行完当前 microtask 队列的所有任务 c) UI render
浏览器只保证 requestAnimationFrame 的回调在重绘之前执行,没有确定的时间,何时重绘由浏览器决定
[参考资料]
- event-loops (opens new window)
- sec-jobs-and-job-queues (opens new window)
- Promises/A+ (opens new window)
- Tasks, microtasks, queues and schedules (opens new window)
- HTML 系列:macrotask 和 microtask (opens new window)
- http://www.ruanyifeng.com/blog/2014/10/event-loop.html
# 深入理解 js 事件循环机制(Node.js 篇)
在浏览器篇 (opens new window)已经对事件循环机制和一些相关的概念作了详细介绍,但主要是针对浏览器端的研究,Node 环境是否也一样呢?先看一个 demo:
setTimeout(() => {
console.log("timer1");
Promise.resolve().then(function() {
console.log("promise1");
});
}, 0);
setTimeout(() => {
console.log("timer2");
Promise.resolve().then(function() {
console.log("promise2");
});
}, 0);
肉眼编译运行一下,蒽,在浏览器的结果就是下面这个了,道理都懂,就不累述了。
timer1
promise1
timer2
promise2
那么 Node 下执行看看,咦。。。奇怪,跟浏览器的运行结果并不一样~
timer1
timer2
promise1
promise2
例子说明,浏览器和 Node.js 的事件循环机制是有区别的,一起来看个究竟吧~
# Node.js 的事件处理
Node.js (opens new window)采用 V8 作为 js 的解析引擎,而 I/O 处理方面使用了自己设计的 libuv,libuv 是一个基于事件驱动的跨平台抽象层,封装了不同操作系统一些底层特性,对外提供统一的 API,事件循环机制也是它里面的实现,核心源码参考 (opens new window):
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
int timeout;
int r;
int ran_pending;
r = uv__loop_alive(loop);
if (!r)
uv__update_time(loop);
while (r != 0 && loop->stop_flag == 0) {
uv__update_time(loop);
// timers阶段
uv__run_timers(loop);
// I/O callbacks阶段
ran_pending = uv__run_pending(loop);
// idle阶段
uv__run_idle(loop);
// prepare阶段
uv__run_prepare(loop);
timeout = 0;
if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)
timeout = uv_backend_timeout(loop);
// poll阶段
uv__io_poll(loop, timeout);
// check阶段
uv__run_check(loop);
// close callbacks阶段
uv__run_closing_handles(loop);
if (mode == UV_RUN_ONCE) {
uv__update_time(loop);
uv__run_timers(loop);
}
r = uv__loop_alive(loop);
if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT)
break;
}
if (loop->stop_flag != 0)
loop->stop_flag = 0;
return r;
}
根据Node.js (opens new window)官方介绍,每次事件循环都包含了 6 个阶段,对应到 libuv 源码中的实现,如下图所示

- timers 阶段:这个阶段执行 timer(
setTimeout、setInterval)的回调 - I/O callbacks 阶段:执行一些系统调用错误,比如网络通信的错误回调
- idle, prepare 阶段:仅 node 内部使用
- poll 阶段:获取新的 I/O 事件, 适当的条件下 node 将阻塞在这里
- check 阶段:执行
setImmediate()的回调 - close callbacks 阶段:执行
socket的close事件回调
我们重点看timers、poll、check这 3 个阶段就好,因为日常开发中的绝大部分异步任务都是在这 3 个阶段处理的。
# timers 阶段
timers 是事件循环的第一个阶段,Node 会去检查有无已过期的 timer,如果有则把它的回调压入 timer 的任务队列中等待执行,事实上,Node 并不能保证 timer 在预设时间到了就会立即执行,因为 Node 对 timer 的过期检查不一定靠谱,它会受机器上其它运行程序影响,或者那个时间点主线程不空闲。比如下面的代码,setTimeout() 和 setImmediate() 的执行顺序是不确定的。
setTimeout(() => {
console.log("timeout");
}, 0);
setImmediate(() => {
console.log("immediate");
});
但是把它们放到一个 I/O 回调里面,就一定是 setImmediate() 先执行,因为 poll 阶段后面就是 check 阶段。
# poll 阶段
poll 阶段主要有 2 个功能:
- 处理 poll 队列的事件
- 当有已超时的 timer,执行它的回调函数
even loop 将同步执行 poll 队列里的回调,直到队列为空或执行的回调达到系统上限(上限具体多少未详),接下来 even loop 会去检查有无预设的setImmediate(),分两种情况:
- 若有预设的
setImmediate(), event loop 将结束 poll 阶段进入 check 阶段,并执行 check 阶段的任务队列 - 若没有预设的
setImmediate(),event loop 将阻塞在该阶段等待
注意一个细节,没有setImmediate()会导致 event loop 阻塞在 poll 阶段,这样之前设置的 timer 岂不是执行不了了?所以咧,在 poll 阶段 event loop 会有一个检查机制,检查 timer 队列是否为空,如果 timer 队列非空,event loop 就开始下一轮事件循环,即重新进入到 timer 阶段。
# check 阶段
setImmediate()的回调会被加入 check 队列中, 从 event loop 的阶段图可以知道,check 阶段的执行顺序在 poll 阶段之后。
# 小结
- event loop 的每个阶段都有一个任务队列
- 当 event loop 到达某个阶段时,将执行该阶段的任务队列,直到队列清空或执行的回调达到系统上限后,才会转入下一个阶段
- 当所有阶段被顺序执行一次后,称 event loop 完成了一个 tick
讲得好有道理,可是没有 demo 我还是理解不全啊,憋急,now!
const fs = require("fs");
fs.readFile("test.txt", () => {
console.log("readFile");
setTimeout(() => {
console.log("timeout");
}, 0);
setImmediate(() => {
console.log("immediate");
});
});
执行结果应该都没有疑问了
readFile
immediate
timeout
# Node.js 与浏览器的 Event Loop 差异
回顾上一篇,浏览器环境下,microtask的任务队列是每个macrotask执行完之后执行。
crotask.png)
而在 Node.js 中,microtask会在事件循环的各个阶段之间执行,也就是一个阶段执行完毕,就会去执行microtask队列的任务。crotask-in-node.png)
# demo 回顾
回顾文章最开始的 demo,全局脚本(main())执行,将 2 个 timer 依次放入 timer 队列,main()执行完毕,调用栈空闲,任务队列开始执行;
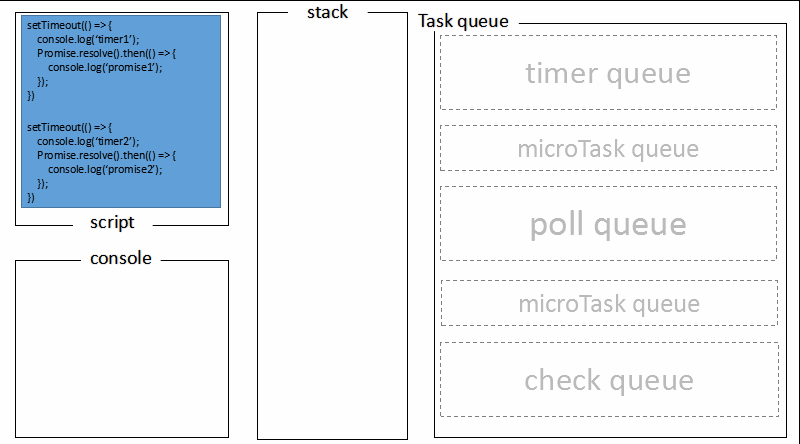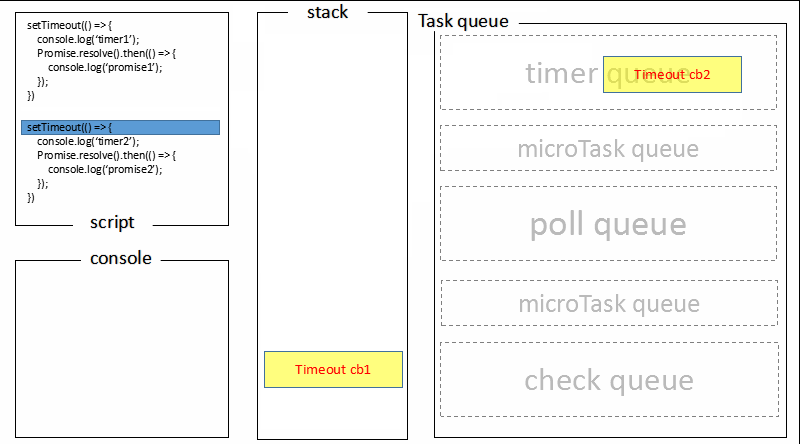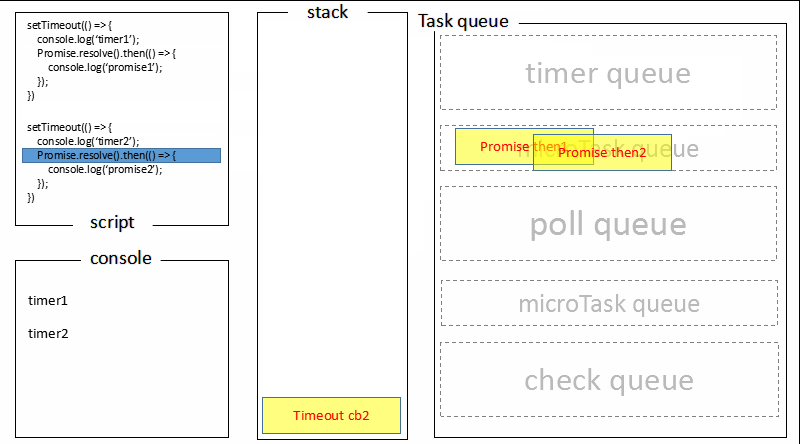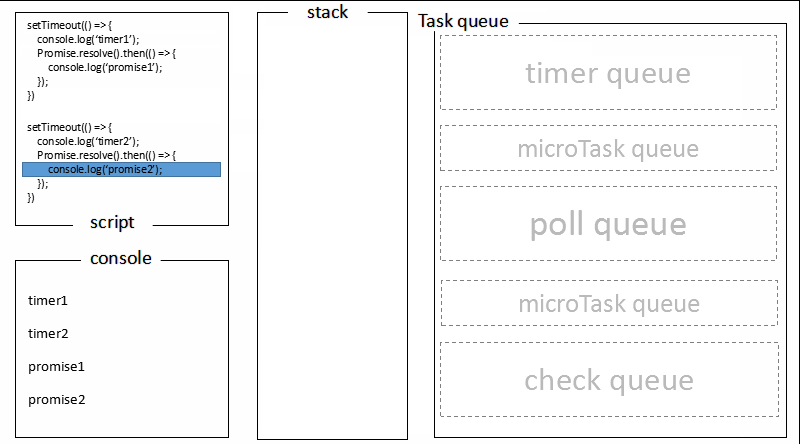
首先进入 timers 阶段,执行 timer1 的回调函数,打印timer1,并将 promise1.then 回调放入 microtask 队列,同样的步骤执行 timer2,打印timer2;
至此,timer 阶段执行结束,event loop 进入下一个阶段之前,执行microtask队列的所有任务,依次打印promise1、promise2。
对比浏览器端的处理过程: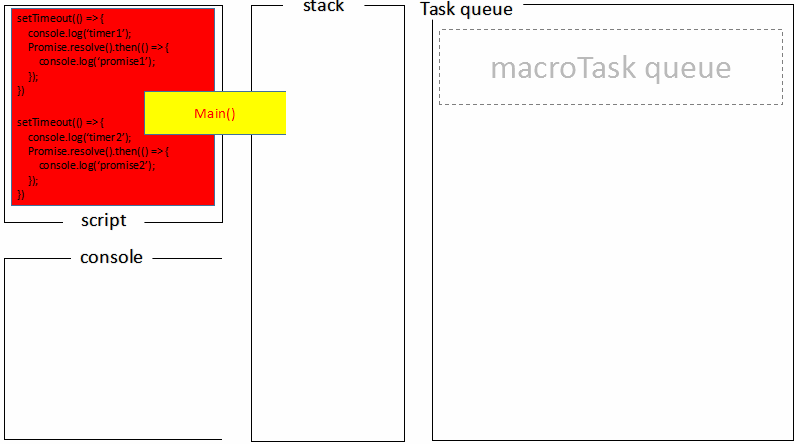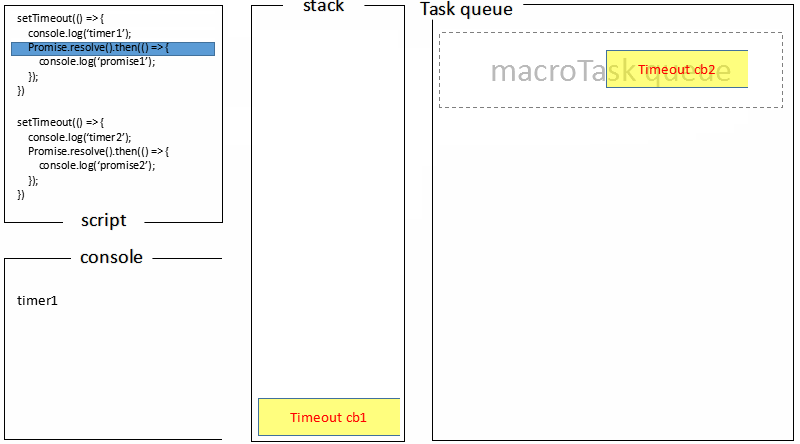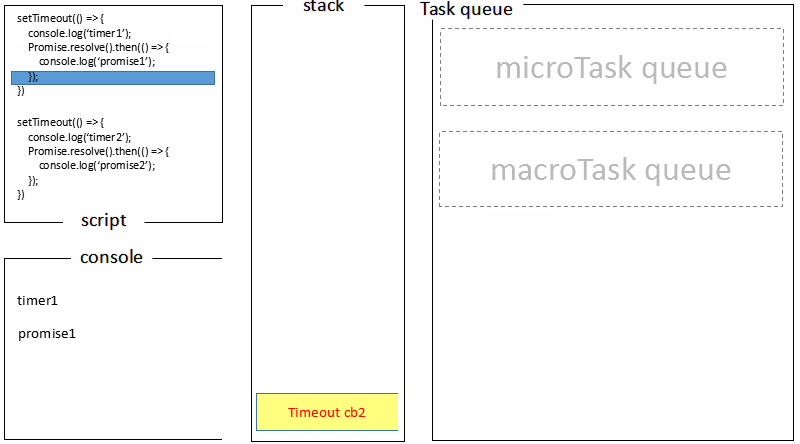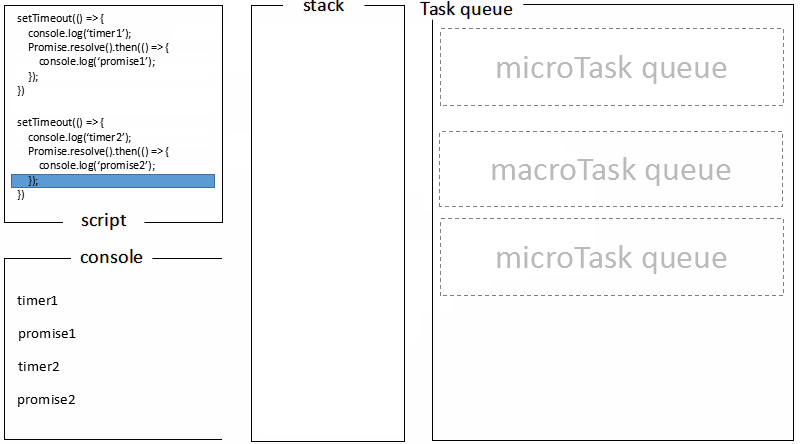
# process.nextTick() VS setImmediate()
In essence, the names should be swapped. process.nextTick() fires more immediately than setImmediate()
来自官方文档有意思的一句话,从语义角度看,setImmediate() 应该比 process.nextTick() 先执行才对,而事实相反,命名是历史原因也很难再变。
process.nextTick() 会在各个事件阶段之间执行,一旦执行,要直到 nextTick 队列被清空,才会进入到下一个事件阶段,所以如果递归调用 process.nextTick(),会导致出现 I/O starving(饥饿)的问题,比如下面例子的 readFile 已经完成,但它的回调一直无法执行:
const fs = require("fs");
const starttime = Date.now();
let endtime;
fs.readFile("text.txt", () => {
endtime = Date.now();
console.log("finish reading time: ", endtime - starttime);
});
let index = 0;
function handler() {
if (index++ >= 1000) return;
console.log(`nextTick ${index}`);
process.nextTick(handler);
// console.log(`setImmediate ${index}`)
// setImmediate(handler)
}
handler();
process.nextTick()的运行结果:
nextTick 1
nextTick 2
......
nextTick 999
nextTick 1000
finish reading time: 170
替换成setImmediate(),运行结果:
setImmediate 1
setImmediate 2
finish reading time: 80
......
setImmediate 999
setImmediate 1000
这是因为嵌套调用的 setImmediate() 回调,被排到了下一次 event loop 才执行,所以不会出现阻塞。
# 总结
Node.js 的事件循环分为 6 个阶段
浏览器和 Node 环境下,
microtask
任务队列的执行时机不同
- Node.js 中,
microtask在事件循环的各个阶段之间执行 - 浏览器端,
microtask在事件循环的macrotask执行完之后执行
- 递归的调用
process.nextTick()会导致 I/O starving,官方推荐使用setImmediate()
[参考资料]